Abstract
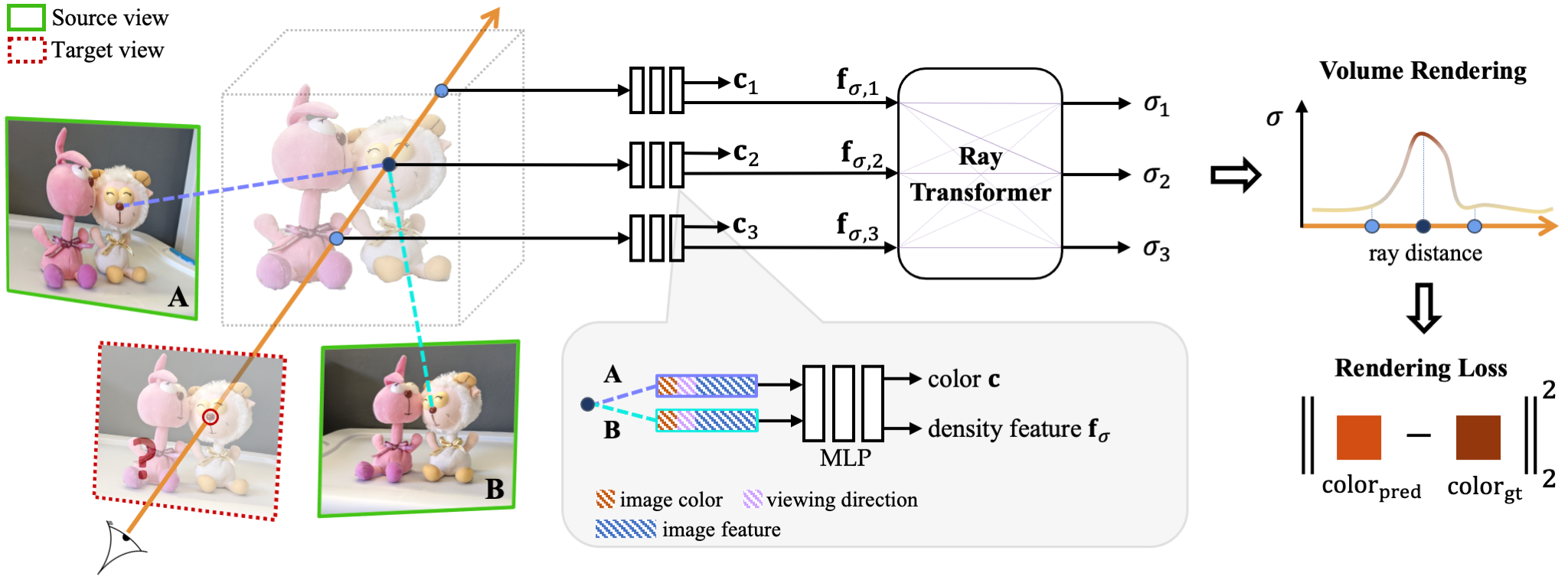
We present a method that synthesizes novel views of complex scenes by interpolating a sparse set of nearby views. The core of our method is a network architecture that includes a multilayer perceptron and a ray transformer that estimates radiance and volume density at continuous 5D locations (3D spatial locations and 2D viewing directions), drawing appearance information on the fly from multiple source views. By drawing on source views at render time, our method hearkens back to classic work on image-based rendering (IBR), and allows us to render high-resolution imagery. Unlike neural scene representation work that optimizes per-scene functions for rendering, we learn a generic view interpolation function that generalizes to novel scenes. We render images using classic volume rendering, which is fully differentiable and allows us to train using only multi-view posed images as supervision. Experiments show that our method outperforms recent novel view synthesis methods that also seek to generalize to novel scenes. Further, if fine-tuned on each scene, our method is competitive with state-of-the-art single-scene neural rendering methods.
Video Comparsion
Ours vs. LLFF
Ours Finetuned vs. NeRF
BibTeX
@inproceedings{wang2021ibrnet,
author = {Wang, Qianqian and Wang, Zhicheng and Genova, Kyle and Srinivasan, Pratul and Zhou, Howard and Barron, Jonathan T. and Martin-Brualla, Ricardo and Snavely, Noah and Funkhouser, Thomas},
title = {IBRNet: Learning Multi-View Image-Based Rendering},
booktitle = {CVPR},
year = {2021}
}